 |
|
IBRI Research Report #10 (1982)
Copyright © 1982 by David C. Bossard. All rights
reserved.
EDITOR'S NOTE
| Although the author is in agreement with the doctrinal statement of IBRI, it does not follow that all of the viewpoints espoused in this paper represent official positions of IBRI. Since one of the purposes of the IBRI report series is to serve as a preprint forum, it is possible that the author has revised some aspects of this work since it was first written. |
ISBN 0-944788-10-6
Introduction
Christians believe that the created universe displays the handiwork of God the Creator. The marks of the Master Craftsman permeate every part of the physical and biological world from the submicroscopic to the telescopic. How can a reasonable person see this evidence and yet maintain an atheistic or agnostic opinion of it all? Is this disbelief the evidence of the perverseness of the human mind clouded by self-deception? Is it the manifestation of the depravity mentioned in Rom 1:18-32? Is mankind suppressing the evident truth in order to maintain a lie? Or does the disbelief arise from genuine doubt as to the implications of the observable facts? Are the doubts well-founded? Can the doubts be resolved by careful argument?
When Jesus was on earth, he had compassion for the multitudes of people about him, because they were as sheep without a shepherd. He mingled with them, talked with them in words that they could understand, using commonly experienced incidents of life to illustrate and persuade these people that he is the Truth. His approach to the people was not conditioned by questions of innocence or guilt; perhaps most of the multitude were willful disbelievers. Nonetheless Jesus went to them and spoke to them at their level of understanding. The romantic notion that the multitudes of Christ's day were innocent victims of oppression by cold and uncaring religious and secular leaders is simply false. When Jesus called them sheep without a shepherd, he did not say innocent sheep. We tend to supply that adjective in our own minds.
It seems strange to talk about compassion for the atheist and agnostic in the same way that one would talk about compassion for the multitude of Christ's day, and yet the difference between the intellectual multitude and the multitude of first century Palestine is not a difference of kind by only a difference of degree (excuse the pun!). They too are sheep without a shepherd. As Jesus went to his sheep and spoke to them at their level of understanding, with compassion and loving concern, so the intellectual multitude needs shepherds who meet them at their level, with compassion.
How does a Christian discuss the handiwork of God with a reasonable person? One obvious need, it would seem, is to use the language and the reasoning processes that his friend is familiar with. The language of science is very structured and logical. If possible, scientists try to express arguments in quantitative form. There are tentative hypotheses, premises, and rules of deduction. The Christian should be familiar with these, and know something both of their potential and limitations.
Particularly, the Christian should understand the limitations of the language. One of the facts of life is that strictly deductive reasoning is very difficult to formulate (or listen to), and the amount of argument needed to come to anything but the simplest conclusions is excessive. In a sense it is like working with a language that has too few words expressing anything but the most direct ideas can be painfully difficult. Because of this limitation, scientists and other intellectuals seldom stick to deductive reasoning it is much more important to convey ideas than it is to follow strict rules of logic. However, being a scientist, the language will still sound scientific whether it is logical or not. A Christian must understand this: a logical, scientific argument is not one that sounds logical and scientific. The key to discussion in such cases is to seek to find the underlying premises of the discussion, and to focus attention on these premises.
With this as an introduction, how can a Christian explain his belief in the created universe to a disbeliever? One approach is to seek ways to quantify his observations: if the marks of the Master Craftsman are there, can the evidence be expressed in numerical terms? Can mathematical and logical reasoning be used to demonstrate that the world could not exist in its present state as the result of random, mindless activity, apart from a Creator? One advantage of the numerical approach, particularly if based on valid mathematical techniques, is that it can lead to clear deductive thought sequences, which is a considerable aid to clarifying the true issues under discussion. The disadvantage of this approach is again the matter of limited language -- it is impossible to address all of the burning issues of the creation controversy in this way, because the language is just not rich enough.
The approach taken here is to pursue the issue of God's handiwork by
contrasting the hypotheses of purpose and orderliness against those of
random, undirected processes; how well does each explain the world as it
appears today? The proper language for discussion purposes is the mathe-
matics of probability theory and information theory. After some preliminary
remarks on the "grammar" of these languages, the arguments of some secular
scientists will be examined to see whether they are consistent with the
language, as well as to see how these authors face the issue of God's handiwork
from their secular perspectives. Particular attention will be given to
the recent discoveries in microbiology and the implications of these discoveries
regarding the handiwork of God. Finally, some philosophical comments --
based on solid mathematical facts -- will be offered regarding the limits
of scientific discussion and the implications for Christian apologetics.
The Language of Probability and Random Events
The science of probability arose because of the strange notion that even random events -- mindless activity -- appear to have a certain orderliness about them. In a random experiment consisting of 100 tosses of a coin, one expects about 50 heads to come up, if the coin is "fair." If all heads came up, one could deduce with high probability that the coin was biased to prefer heads to tails (or more likely, the coin had two heads!). Probability calculations make it possible to deduce precisely the probability of a given outcome based on assumptions regarding the elementary event (here, the toss of a coin).
One of the interesting facts of probability theory is that posterior analysis -- examining the outcome after the event occurs -- can appear to show the presence of orderliness when in fact the outcome is random. To give an example, in a thousand tosses of a coin, it would not be unusual to have ten heads in a row at some point. The mind seems to have a perverse tendency to read order into such outcomes, with the result that false inferences are possible. The continual (and futile) quest for "hot dice" in a gambling casino is an example of how the mind can be fooled by such random occurrences. Many people argue that "technical analysis" of stock market prices is another example of the pursuit of seeming order in random activity.
When Christians argue that the apparent orderliness in the created universe displays the handiwork of God, the "reasonable person" who disagrees may be saying, in effect, that the apparent order is the result of random events. One person who takes this viewpoint is George Wald, a Harvard professor and Nobel laureate in biology. He wrote a very interesting article in the August, 1954 Scientific American in which he gives the following development of the scientific view of the origin of life.1
Prior to the Enlightenment, he says, the prevailing Western view was that life was created by God.
| The more rational elements of society, however, tended to take a more
naturalistic
view of the matter. One had only to accept the evidence of one's senses to know that life arises regularly from the nonliving: worms from mud, maggots from decaying meat, mice from refuse of various kinds. This is the view that came to be called spontaneous generation. Few scientists doubted it. Aristotle, Newton, William Harvey, Descartes, van Halmont, all accepted spontaneous generation without serious question. Indeed even the theologians . . . could subscribe to this view, for Genesis tells us, not that God created plants and most animals directly, but that he bade the earth and waters to bring them forth; since this directive was never rescinded, there is nothing heretical in believing that the process has continued. But step by step, in a great controversy that spread over two centuries,
this belief
|
Wald goes on to describe Pasteur's first great experiment in which he showed that mold and maggots do not appear spontaneously in a nutritive broth. He then continues:
| This was only one of Pasteur's experiments. It is not easy matter to
deal with so
deeply ingrained and common-sense a belief as that in spontaneous generation. . . . When he had finished, nothing remained of the belief in spontaneous generation. We tell this story to beginning students of biology as though it represents
a triumph
|
Wald then goes on to state that a scientist "has no choice but to approach the origin of life through a hypothesis of spontaneous generation." He proceeds to describe what is involved in making an organism:
| Organic molecules (therefore) form a large and formidable array, endless
in variety
and of the most bewildering complexity. One cannot think of having organisms without them. This is precisely the trouble, for to understand how organisms originated we must first of all explain how such complicated molecules could come into being. And this is only the beginning. To make an organism requires not only a tremendous variety of these substances, in adequate amounts and proper proportions, but also just the right arrangement of them. Structure here is as important as composition and what a compli- cation of structure! The most complex machine man has devised -- say an electronic brain -- is child's play compared with the simplest of living organisms. The especially trying thing is that complexity here involves such small dimensions. It is on the molecular level; it consists of a detailed fitting of molecule to molecule such as no chemist can attempt. One has only to contemplate the magnitude of this task to concede
that spontaneous
|
In the remainder of the article, Wald goes on to argue that perhaps the impossible is not so impossible after all. He uses two lines of argument. First, he says that the "impossibility" of spontaneous generation is valid only as perceived by the scientists who operate in local time spanning a few multiples of a lifetime. However, viewed from the perspective of geological time:
| Given so much time, the "impossible" becomes possible, the possible
probable,
and the probable virtually certain. |
This last argument is in essence a statement about the calculus of probability. However small the likelihood of a given result in an experiment, it will surely occur if the experiment is repeated often enough. Wald's second argument concerns information theory and will be discussed later in this paper.
In effect, Wald says that the universe only apparently shows the evidence of God's handiwork; in fact, it is the result of random activity. How can a Christian respond to this assertion? One way is to check the calculations. Recall that Wald, though a scientist talking very persuasively in scientific language, is not really presenting a logical deductive argument. To be fair, he could hardly do so, because his article covers too much ground, and is directed to non-scientists. In order to fill in the gaps, it is necessary to give some of the facts about probability theory, which form the basis of all valid probability calculations.
There are four components to a probability calculation: a space, a field, a measure, and a calculus. These are technical terms with very specific meanings that are well-known to mathematicians. For our purposes the following simplified definitions will suffice. These definitions are not complete; for a full definition, see an elementary textbook on probability.
A space is the set of objects under discussion for a given probability calculation. Examples of a probability space are:
A field is the way that the probability space is divided. For those who have studied modern mathematics, this corresponds to subsets of the space. In the arguments discussed below, the field is trivial, i.e., every member of the space is considered individually. In fact, so long as the space is finite, this is the only field of interest in probability arguments. Questions concerning the nature of the field begin to be important when the space is uncountably infinite for example: if the space is the surface of the earth, or the volume of the visible universe, then the field may be areas or volumes, rather than points; probability arguments would then concern events that happen in areas or volumes.
A measure is the probability assignment that is placed on each element of the field. In the case of a finite space, every member of the space has a probability value and these must sum up to one. For example, if each of the life-supporting amino acids is equally abundant in nature, then the probability assigned to each acid is the probability that it will be selected in a random draw (1/20). On the other hand, if the purpose for considering the letters of the alphabet is to study the formation of English language words, or messages consisting of such words, then it may be more appropriate to assign probabilities to each letter that correspond to the frequency that the letter occurs in intelligible text.
A calculus is the rules used to form deductive probability statements. For example, the calculus tells us how to compute the probability of a given chain of amino acids or a given word in the English language. The calculus involves assumptions about the method of combination, and it is important to know what these assumptions are, because the rules of the calculus are heavily dependent on the assumptions used. A key assumption that is often made in the calculus of probability is independence, which means that the probability that a given sequence of random trials will produce a specific result is the product of the measures assigned to each trial. Thus, with the assumption of independence, the probability that a given chain of N amino acids would occur in a particular order is given by
P = (1/20)N = 1/20 x 1/20 x 1/20 x ... x 1/20 (N times),
if the chain is obtained by a draw of N amino acids selected independently, for a source where each variety of amino acids is equally available and equally abundant. Note the qualifiers; a probability assignment is meaningless unless the underlying qualifiers are understood.
When disagreements arise in the interpretation of probability calculations, the source of disagreement will be found in one of the four components of probability theory the space, the field, the measure, or the calculus. It is important to keep this in mind. It may be possible and even enlightening to work at agreement in these areas, rather than to rest the discussion with disagreement over the final calculation. To give a trivial example of how legitimate disagreements may arise, consider the question of word frequency in the English language. A calculus that attempts to compute word frequency by assuming independence in the combination of individual letters will surely come to grief, because it would be unable to account for the fact that the letter "Q" only occurs in combination with "U" and that "UQ" has an entirely different probability of occurrence (namely zero) than "QU." The problem here is not the result, but the assumption of independence that led to the result.
Return now and consider Wald's argument. The subject of his discussion is the spontaneous appearance of life. In the last-quoted statement he makes the assertion that the spontaneous generation is life is "virtually certain" given enough time. This sounds like a probability argument -- what is his space, his field, etc.? Of course one finds that these are unstated; in fact his argument is not scientifically based at all, at least not in the way he presented it. Could an appropriate probabilistic argument be constructed? Yes, such an argument might be given, but it would be immensely complicated. However, one can construct a much simpler argument that provides an upper bound on the probability that Wald talks about. The simpler question is the probability of spontaneous generation of a life-supporting protein. This is far from spontaneous generation of life, and so the probability of spontaneous life must be much less than the probability of spontaneous protein formation.
In order to proceed, it is necessary to review some vital information
about the remarkable processes that take place in every living cell, from
the simplest to the most complex. This information is summarized from two
pamphlets published by the U.S. government.2 Interestingly,
most of this information was discovered after Wald's article appeared.
Life Processes in the Cell
Nearly every high school student has heard of the famous experiments with sweet pea plants that were conducted by the Australian monk Gregor Mendel in the middle of the 19th century. These experiments resulted in the discovery of genes, mysterious components of reproductive cells that carry hereditary characteristics. In the course of his experiments, Mendel proved that genes from parents having different hereditary traits combine according to definite probabilistic rules to produce traits in the offspring and the offspring's own descendants.
Mendel proved that genes are real, but it was a long time before scientists could locate and identify them. In the 1920's it was shown that genes are located in long thread-like objects called chromosomes, and that the order of genes in the chromosomes is related to the fact that certain hereditary traits seem to occur together. Genes which are located close together in a chromosome tend to be more strongly linked than genes which are separated by some distance. It is as if the chromosomes were cut in pieces and patched together in the offspring genes in the same piece would be carried intact to the offspring, so nearby genes would tend to be inherited together.
During the 1940's it was discovered that genes are made up of DNA (deoxyribonucleic
acid) which is a large but uncomplicated molecule built up of four basic
building blocks called
nucleotides -- adenine, thymine, guanine,
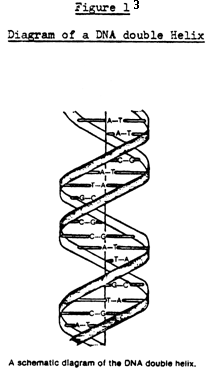
and cytosine, denoted A, T, G, and C for short. In 1953 the structure of
the DNA molecule was discovered, along with the means by which it reproduces
itself. The DNA takes the form of a double helix, each of the two strands
consisting of a long sequence of the nucleotides. The second strand of
the helix is complementary to the first, with a corresponding order of
nucleotides in which A is interchanged with T, and G with C. Figure 1 gives
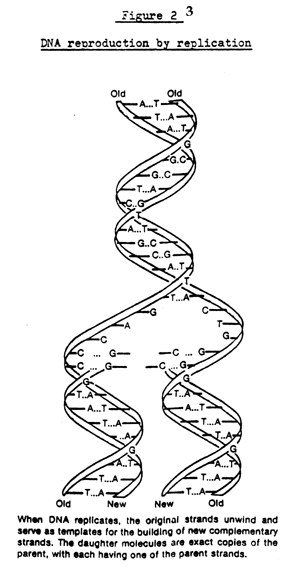
a sketch of this arrangement. When a DNA molecule reproduces, the two strands
separate, and each of them forms a new second strand to match the one it
separated from, as illustrated in figure 2. The effect is rather like a
zipper which opens up and then assembles a new half-zipper to match each
open half. Each side of the zipper forms an accurate template for the original
complete DNA molecule, to which nucleotides floating in the cell fluid
are carried and attached. The actual building mechanism will be discussed
below in connection with protein formation.
 |
 |
All cells, from simplest to most complex, have large amounts of DNA. It has been estimated that every adult human carries about 100 billion miles of DNA strands in his or her body enough if stretched end-to-end to span the solar system.4
Two important facts stand out in the discoveries mentioned thus far. First, reproduction of life requires pre-existing building blocks which exist in abundance in a life-supporting fluid. DNA does not create the matching strand from "scratch" it requires pre-existent nucleotides. This dependence of the reproduction mechanism on the availability of other pre-existent molecular structures outside of itself is characteristic of all life. At every step, the continuation of life requires previous life forms. Second, the characteristics which define a species (and the minute variations within a species) are somehow coded in the elaborate structure of DNA and are transmitted from one generation to another by the template-matching process just discussed. This template matching is what assures faithful reproduction of species. No life is formed, as far as is known, without a pre-existing template. Even the simplest life form has thousands of elaborate DNA molecules, with elaborate genetic coding included.
Describing the structure of DNA is only the first step in understanding the complicated cell mechanisms. The DNA is the brain, so to speak, of the cell, but the proteins are the workers. No life can exist without proteins. How are they manufactured? Since different species have different proteins, clearly the genetic coding of the DNA has something to do with their formation. How is this done? It is only in the past twenty years, and especially in the last decade that the answers to this have begun to become understood.
Each gene consists of perhaps 2000 nucleotide pairs matched in the double helix. In the early 1960's it was found that the genetic information is built up from triplets of nucleotides. Each triplet forms a genetic "word" and uniquely identifies a particular amino acid (of which there are twenty) or indicates the beginning or end of a message sequence. Proteins are built up of amino acids in the order dictated by the genetic code.
| By the early 1980's, the way proteins were manufactured, how their
synthesis was
regulated, and the role of DNA in both processes were understood in considerable detail. The process of transcribing DNA's message carrying the message to the cell's miniature protein factories and building proteins took place through a complex set of reactions. Each amino acid in the protein chain was represented by three nucleotides from the DNA. That three-base unit acted as a word in a DNA sentence that spelled out each protein -- the genetic code. Through the genetic code, an entire gene a linear assemblage of nucleotides
could
|
Given this understanding of fundamental life processes, it is now possible to return to Wald's assertion in order to see whether useful information is possible. From what is now known, proteins are constructed from blueprints, by a copying process. Scientists have even come to the place where it is possible to construct a synthetic "blueprint" and then have a protein manufactured according to the scientist's concoction. But how did the first living proteins get constructed? Where was the blueprint?
It is well-known among scientists that even a single error in the coding sequence for a protein can result in a disastrous mutation that inhibits rather than supports life. For example, a hemoglobin protein consists of some 300 amino acids. Sickle-cell anemia, a genetic disorder which disturbs the ability of the blood cells to perform effectively, is the result of the faulty placement of a single amino acid.
Because of the way that DNA molecules and proteins are built up from relatively few types of components, it is quite possible to construct probability arguments to show that the chance production of a single one of the life-supporting proteins is exceedingly unlikely. Fred Hoyle, Nobel laureate in astronomy, discusses the problem in his recent book, Ten Faces of the Universe. He writes concerning the origin of life:6
| We would have a straightforward answer to this question if we could
reasonably argue
that the initial arrangement of a living cell was due to chance. But a probability calculation soon shows that such an explanation is not reasonable, that we are faced with a strange situation. Even the least complex protein that is biologically important is made up from about a hundred amino acids linked to form a long chain. Each link in the chain consists of one particular amino acid taken from a set of twenty. Yet with twenty possibilities for each link, there are 20100 possible distinct proteins that have a hundred links. How was the particular arrangement that is biologically important picked out from this enormous number of possibilities? In a suitable environment, many arrangements would certainly be tried, but not remotely as many as 20100. The total number of amino acids on the whole earth cannot have been much more than 1044. If each one were involved every few seconds in a new trial, even four billion years would not be time for more than about 1060 trials, vastly less than the 20100 trials needed. Even for all the 1020 possible planetary systems in the observable universe, there would only be about 1080 trials, still much less than 20100 [=10130]. Plainly then, most of the ways in which amino acids might be linked to form proteins can never have been tried, not even once in the history of the whole of the visible universe. [Emphasis added.] |
Elsewhere in the same book, Hoyle states,
| From the standpoint of biology, our presence on the Earth depends on
a remarkable
and even fantastic sequence of chemical processes. From the standpoint of physics, the very material of which we are constituted has experienced an evolution scarcely less remarkable. |
Concerning evolutionary selection, Hoyle says,
| But could such a process produce the exceedingly rich aggregate of
plants and animals
that has emerged on the Earth during the past 500 million years? Charles Darwin answered this question affirmatively in his book Origin of Species. By noting variety changes in birds and plants, Darwin sought to estimate the dynamic rate of the evolu- tionary process. His conclusion was that the rate was sufficient to explain the changes . . . . Although this analysis constituted a crucial advance of biological thinking in the mid-nineteenth century, it is scarcely adequate to meet our twentieth-century curiosity. Indeed, I think today we can even feel some sympathy for Darwin's opponents in the classical debate which followed the publication of The Origin of Species. The counter-argument, phrased in modern terms, starts by noting the enormous quantity of information required to specify the structures of plants and animals. What was the source of this information? Darwin's researches showed how the information might be shuffled about, but the source of the information was not identified. The implication of nineteenth-century biology seemed to be that the code had somehow been generated spontaneously, essentially out of nothing. This view is unlikely to be correct, how- ever, because the chance that many individual cells could shuffle themselves by a random process into a complex life form is exceedingly small. |
Despite these observations, Hoyle, like Wald, accepts these facts, remarkable as they are, against the alternative of a Creator. Wald and Hoyle both assert that there are unknown natural laws that organic substances follow that result in rapid, almost directed, evolutionary development. The "enormous quantity of information" is not really so great because it is the by-product of these laws.
The probability calculation made by Hoyle in conjunction with protein formation is extremely interesting. It is a typical rough calculation that is often a good "sanity check" to test qualitative or intuitive ideas. Scientists often use such calculations as an exploratory probe to find areas that merit more careful analysis. Of particular interest is the implication in Hoyle's calculation that Wald's intuitive remarks about the effect of geological time making the rare event of protein formation "virtually certain" are not only wrong, but miss the facts by a wide margin. Even geological time and the entire observable universe will not suffice.
Hoyle chose one of two possible ways that the first proteins might have been formed by random action. He assumed random formation of the proteins directly, without the help of a template. A second way to form the protein is with the aid of a template. This pushes the problem back one step how was the first template formed? There seems to be a tendency among some current biologists to take the template approach, arguing that primordial mud may have accidentally provided a suitable template for the formation of the first living proteins. Astronomer Carl Sagan, in his popular television series "Cosmos," has suggested this in discussing the results of various tests for life-supporting organic molecules in recent NASA interplanetary probes. He notes that some types of clay seem to be conducive to the assembly of organic molecules. It is not possible to pursue this line further here, but it may represent a future direction in scientific thought.
Actually, Hoyle's argument has a minor error in the probability calculus: it does not take 20100 trials to turn up an event that has a probability of 20-100. A more accurate formulation is as follows. Suppose that there are about 1012 (one trillion, in US usage) different proteins in the plant and animal kingdom, and the random production of any one of these would be scored a success. Assume for convenience that all of these proteins have length of at least 100. If each amino acid is selected at random from the 20 possible life-supporting amino acids, and each acid is equally likely to be selected in a random draw (probability 1/20), then the probability that a protein chain of amino acids will be one of the 1012 life-supporting proteins is 1012/20100. Over the course of 1080 independent trials, using the number quoted by Hoyle, the probability of producing at least one life-supporting protein is
P = 1 - (1 - 1012/20100)N, where N = 1080.
This quantity can be evaluated approximately by a simple mathematical trick involving the exponential function (which appears on most scientific calculators).
P = 1 - exp (-101220-1001080)
= 1 - exp (-2-10010-8)
= 10-38
This probability is comparable to the chance of finding a particular grain of sand in a sandpile the size of the earth (the earth's mass is only 1026 grams) with one random draw.
What does this probability calculation show? At the very least, it shows that Wald's remark was a little hasty. But does it prove that God's handiwork was responsible for the protein molecule? The answer is no, because the computation is based on numerous debatable assumptions. For one thing, it is unlikely that the assumption of independence is appropriate when considering the formation of a protein from 100 amino acids, because of the complex chemical interactions and bonding involved. So in this sense the model is an over-simplification which has a unknown effect on the accuracy of the probability calculation. Secondly, what is the actual size of the space of all possible life-supporting proteins? Can it be shown to be of the order of 1012 rather than 20100?
On the other hand, the production of a mere life-supporting molecule is by no means equivalent to the creation of life the total life-support system of a cell is vastly more complex than this and involves intricate interdependencies. But at least the calculation does show that the evolutionist must look elsewhere for a plausible argument for chance formation of life.
It is a scientific fact that some simple organic compounds can be found
and produced by non-organic means. Amino acids, which typically involve
10 to 30 atoms, have been found in extra-terrestrial matter. In the light
of the preceding calculation, this does not seem overly surprising from
a purely combinatorial consideration. However, living matter involves vastly
greater complexity than amino acids. The only way that secular scientists
can argue that life arose naturally is by postulating powerful unknown
mechanisms which have the effect of focusing random activity in the narrow
channel that leads to life.
Information and Coding
The discussion thus far has concentrated on purely probabilistic argumentation. Could the perceived order be in fact the result of random mechanisms? At least by the one hypothetical construction considered, the answer is clearly negative.
A second approach is to attempt to quantify the level of information involved in life processes. Can it be shown that the amount is too large to be accounted for apart from God?
Discussions of information involve, in addition to the probabilistic concepts mentioned previously, some additional concepts. Information is carried in a channel or medium, and exists in a code determined by coding algorithms or rules. The DNA molecule is a channel of information, as is the printed text of a book. The algorithms in the case of DNA would be the rules which govern the way that genetic information is recorded in the molecule, and the code is the resultant sequence of nucleotides that incorporate this genetic information. In the case of a printed text, the algorithms are the rules of grammar, including spelling rules, and the words are the code. In most printed texts, there is no attempt to obscure the information, so the coding algorithms give clear, unambiguous meaning to the coded information. When the intent is to obscure the meaning, the coding algorithms are called "encryption algorithms."
Legitimate questions which can be addressed in information theory include:
2. Can the actual content of an information channel be determined -- what is the coding scheme and can it be deciphered?
3. How can the presence of information be recognized?
In Wald's article, after presenting the remarks already quoted, the author goes on to discuss the apparently large information content of living matter. He writes:7
| To form an organism, molecules must enter into intricate designs and
connections;
they must eventually form a self-repairing, self-constructing dynamic machine. For a time this problem of molecular arrangement seemed to present an almost insuperable obstacle in the way of imagining a spontaneous origin of life, or indeed the laboratory synthesis of a living organism. It is still a large and mysterious problem, but it no longer seems insuperable. The change in view has come about because we now realize that it is not altogether necessary to bring order into this situation; a great deal of order is implicit in the molecules themselves. |
Wald goes on to observe that crystals appear to have very complex structures, although the structure can be explained by a relative handful of physical laws. By analogy, he argues that the apparent complexity of life may result from the application of a relative handful of as-yet-unknown laws. Therefore, the information content may in fact be far less than appears on the surface. Wald fortifies his remarks with the observation that recent experiments with muscle fibers show that when the fibers are dissolved and re-precipitated under proper conditions, "the molecules realign with regard to one another to regenerate with extraordinary fidelity the original patterns of the tissues."
There are some interesting parallels in the history of science that help to illustrate the point that Wald is attempting to make. Prior to the time of Johannes Kepler, scientists had attempted to describe the motions of the planets by means of very elaborate schemes. Ptolemy, in the second century AD, set forth his theory of planetary motion in a 13 volume work, the Almagest. For Ptolemy, the earth was the center of the universe. Planetary motion was described by circular motion of an elaborate sort circles within circles that in fact agreed well with the known astronomical data. Kepler replaced all this with a set of equations that could be written down on a postcard, with room to spare. His equations are still used today to describe the paths of ballistic missiles in space and other astronomical objects.
One way to quantify the amount of information in a message is to count the number of symbols required to encode it. By this criterion, the actual information content of the planetary motion, as demonstrated by Kepler, is far less than would have been assumed by Ptolemy and his followers. Just so, Wald argues, the complexity observed in life processes must be illusory; behind the observed complications lie simple laws that control the structure.
In one sense, there is really no way to refute such assertions. Surely once unknown laws lie behind and control many processes we understand today, and this may well be the case for currently mystifying situations. There is no way to prove, for example, that something which is currently described by 1000 words could not be described most efficiently by 10 words. Informa- tion theory can state the maximum capacity of a channel containing 1000 words, but it cannot evaluate the actual information content being used in most interesting cases. If, as with Kepler's laws, a stroke of genius discovers a 10-word sequence that carries all the information of the earlier 1000 words, then mathematics can be used to prove the equivalence, and information theory then gives a new upper bound on the information content of the message based now on the 10-word version.
Rather than attempt a direct refutation of Wald's assertion, it is instructive
to look more deeply into the information and coding mechanisms of life
processes, to see how plausible his argument really is. The discussion
given above on the structure of DNA and proteins only scratches the surface
of the amazing facts about the methods used to encode and transfer information
with the living cell.
Coding and Information Transfer in Living Cells
The means by which a living cell stores genetic information and uses it to carry on life processes is one of the most fascinating studies in modern science and the quest is still continuing. An excellent non-technical exposition of the subject, besides the two publications mentioned previously, is Douglas R. Hofstadter's book Goedel, Escher, Bach: An Eternal Golden Braid, which will also figure in later discussions in this paper.8
As mentioned before, the DNA molecule is a long chain of coded genetic information; it apparently controls the formation of all the life matter of the living cell. Therefore, DNA can be considered a channel of information. Its capacity is enormous. Every human cell has about eight feet of DNA, totalling about 1012 (a trillion, in US usage) nucleotides. Single DNA molecules are estimated to be perhaps 10 centimeters in length if stretched out, containing some billion (109) nucleotides. By comparison, a large encyclopedia may contain 50 million words, so that a single DNA molecule has the capacity for more information than a large encyclopedia.
There is evidence that the genetic code contained in DNA is stored in a redundant fashion. In other words, the same genetic information appears at multiple locations along the DNA strand. This dispersion of information works to protect against loss of data through damage to a portion of the chain, just as backup diskettes protect against loss of computer files. The brain operates in much the same way: significant sections of the brain can be damaged without loss of data. Because of this redundancy, DNA has a capacity to engineer self-repairs for certain types of damage. This is technically known as error-correcting code.
The actual process of generating proteins and conducting the various life-supporting operations takes place away from the DNA, and
| depends on extraordinarily complicated cellular chemical processes
which are not
coded for in the DNA itself. The DNA relies on the fact that they will happen, but does not seem to contain any code which brings them about. Thus we have two conflicting views on the nature of information in a genotype. One view says that so much of the information is outside the DNA that it is not reasonable to look upon the DNA as anything more than a very intricate set of triggers, like a sequence of buttons on a jukebox; another view says that the information is all there, but in a very implicit form.9 |
In a sense, the DNA molecule is like a computer with a full data bank of information. The question Hofstadter poses is, Who runs the computer?
The actual mechanism of the information transfer from the DNA to the cell has been discovered in the past 25 years. It is described in the Central Dogma of molecular biology. There are special proteins called enzymes which control every life process in the cell. Each distinct operation has its own specialized enzyme. The enzymes can be viewed as the foremen in the cell-factory; they make things happen. The laborers are another kind of molecule constructed of proteins and ribonucleic acid (RNA). Messenger RNA (mRNA) transfers genetic codes from the DNA to a place outside the nucleus where the actual protein production takes place. Transfer RNA (tRNA) transports the individual amino acids to the mRNA for the actually assembly of the proteins.
To produce a particular protein, the corresponding enzyme for its production moves to the portion of the DNA which has the proper genetic code and copies the code, assembling an mRNA molecule in the process. The mRNA molecule when completed looks like a mirror image of the DNA code, or perhaps hand-in-glove is more accurate, since it is made from complementary building blocks, similar to the DNA pairing of A with T and G with C. This mRNA molecule then moves out into the cytoplasm (the main fluid portion of the cell outside the nucleus), to a structure called a ribosome, where another kind of enzyme attaches to it to perform the actual protein synthesis.
There is a special form of tRNA molecule to correspond to each kind of amino acid. At one end of the tRNA is the amino acid, loosely bound by chemical attraction; at the other end of the tRNA is the corresponding "word" of three nucleotides that forms the genetic code for the particular amino acid. As the protein-producing enzyme moves along the mRNA, it advances one word at a time, attracts the corresponding tRNA molecule which is floating in the cytoplasm, and strips off the amino acid for use in building the protein chain.
A single mRNA code for a protein may have several thousand words. As one enzyme moves along the molecule, another enzyme can start a new protein synthesis. Thus at the same time the mRNA may be used to produce many copies of the same protein. It has been possible to make electron microscope photographs of this process (actually of a similar process used to produce the RNA base). The photo shows dozens of nascent molecules in progressive states of construction looking rather like a Christmas tree, with the newly started molecules forming the short top branches and the more developed forms the longer bottom branches.10
The Central Dogma summarizes this process: DNA > RNA > Proteins, with the transition arrows implemented by specific enzymes. Truly this is a wonderful process. Where is the seat of information that directs this activity? Is it explicable purely in terms of chemical reactions? The whole process is intricately interwoven: enzymes are themselves proteins which were produced by enzymes acting on mRNA and tRNA, which in turn were produced by enzymes from the genetic code in DNA. Even the self-duplication of DNA requires special enzymes to take place. Even if the process of cell metabolism can be completely explained, how did it all begin? Hofstadter summarizes the situation as follows:
| We have been talking about these wonderful beasts called ribosomes;
but what are they
themselves composed of? How are they made? Ribosomes are composed of two types of things: (1) various kinds of proteins, and (2) another kind of RNA, called ribosomal RNA (rRNA). Thus in order for a ribosome to be made, certain kinds of proteins must be present, and rRNA must be present. Of course, for proteins to be present, ribosomes must be there to make them. So how do you get around the vicious circle? Which comes first -- the ribosome or the protein? Which makes which? Of course there is no answer because one always traces things back to previous members of the same class -- just as with the chicken-and-the-egg question -- until everything vanishes over the horizon of time.11 |
Note the causal march into the sunset over the horizon of time. Untied strands of this sort are not accidental in Hofstadter's book: they are a designed part of the whole book's theme, which is that the world is filled with "strange loops." We will return to this subject later in the paper.
To round out the discussion of information in the cell, it is necessary to observe that the sequence of amino acids is only the first level of information-conveying structure in the protein molecule. Molecular biologists talk about four level of structure, of which this is the primary level. The secondary structure is the folding of the protein chain into geometric configurations such as sheets and helical chains. The tertiary structure is the final three-dimensional form that the molecule assumes. The quaternary structure is the grouping of parts of the molecule into three-dimensional substructures which have special functions. It is believed that all of the higher level structures are uniquely determined by the primary structure, due to the complex chemical interactions that result. The higher levels of structure are very significant in determining the function of the molecule for example, by creating "pockets" in the structure where certain reactions can take place which constitute the purpose for which the molecule is made. In a sense, then, the original code in the DNA is at least two stages removed from the final function (1) the DNA words represent amino acids, and (2) the arrangement of amino acids imply complex structures which are congenial to desired chemical reactions. It is because of the direct connection between the code sequence and the higher level structures that a single error in the code can cause profound changes in the function of the protein molecule.
Implicit in this discussion of protein formation is an amazing underlying transport mechanism. How is the traffic of a cell policed? There is not only internal traffic as between the DNA and the cytoplasm but also traffic and communications between the cell interior and the external world. Recent research reveals that the communications mechanism is itself implemented by complex indirect information transfer. For example, the role of a cell membrane has been described as follows:
| Besides directing traffic in and out of the cell . . . the plasma membrane
controls
the cell's communications system, receiving signals from the outer environment (including signals from other cells) and sending out messages of its own. Some of these signals are carried by the chemical messengers called
hormones,
|
Our discussion has only touched the surface of the complexities of life's mechanisms in the cell. There are many distinct organelles that make up a cell's structure; each has a very specific function and its own complex structure that is only now being revealed to biologists. It would not be surprising to find that DNA is only one of many comparably complex sources of information responsible for cell life.
To summarize, it is evident that there are two types of information structures manifested in the cell. One structure, represented by the DNA nucleotide chain, appears to contain vast amounts of primary information; that is, information that cannot be derived from simple cause and effect mechanisms (except by the copying process which duplicates previously existing information). The other structure, represented by the higher geometric structures of the protein molecule, contains intricate secondary information, that is, information that can be deduced by a "grammar" from primary information. The grammar in this case is presumed to be the chemical laws of interaction, analogous to the example given previously of interplanetary motions for which Kepler's laws provide the grammar. The significance of secondary information is that it appears to contain more information than in fact it does: the channel of information is bloated, so to speak, as Ptolemy's planetary scheme was.
What Wald and Hoyle are really saying is that the DNA coding (and all
other sources of information in the cell) are in reality only secondary
information, with perhaps a small amount of primary information thrown
in, such as could be generated naturally by a few billion years of random
events. As was seen in the probability calculation on the chance formation
of a simple protein molecule, this assertion leaves very little room for
primary information even a few hundred pieces of independent primary information,
encoded in just the right way and critical to the existence of life, would
be very hard to come by through the mechanisms of pure chance.
Genetic Engineering
Before leaving the subject of molecular biology, it may be worth noting a few facts about genetic engineering which are relevant to the Christian view of the uniqueness of life. The question of creating life in a test tube is one that raises all sorts of emotions from Christians, ranging from flat denial that such is possible, to implications that such efforts are inherently fraudulent. Somewhere in between these extremes is the capitulation to the secular scientists who claim that life does not require special creation. Some comments regarding the present state of progress in genetic engineering may help us to reach an informed position on the matter.
The amount of genetic engineering that is currently possible and in fact is being done daily is significant. The key to genetic engineering is knowledge of the genetic key, and the ability to completely describe the genetic key sequence required to produce known (and unknown) organic molecules. In addition, techniques have been devised by which a gene can be "cut" into pieces and rearranged to form a new genetic key. This process is called gene splicing.13 It is possible to alter a gene in this way, insert it into a living cell, and have the altered gene faithfully reproduced in daughter cells, along with the new protein implied by the new gene structure. In fact, this use of a "host" cell to propogate foreign DNA is nothing new in nature: certain bacteria and viruses have used this technique since the beginning of life. To work, it is only necessary to overcome some defense mechanisms built into the cells again by genetic engineering or other procedures.
The potential risks as well as potential rewards of genetic engineering are profound. Whereas normal chemistry merely produces a possibly lethal substance, genetic engineering produces a substance capable of self-reproduction! This is a fact, not conjecture. Furthermore, because the "tinkering" can take place at the very seat of life itself, the possibility exists of producing complete organisms, including human beings, with deliberately altered genetic make-up.
The theological and ethical implications of this are chilling and raise the specter of humanoids and engineered master races, but genetic engineering by no means constitutes creation of life. Concern for the dangers of genetic engineering has led to the establishment of guidlines by the National Institutes of Health, which apply to all research involving DNA molecules in the United States. Benefits derived from genetic engineering have already begun to arrive: the artificial production of insulin and various hormones, for example14
Could we eventually produce a self-reproducing "living" cell entirely from non-living materials? The answer to this depends on several factors. First is the information question: is all of the life force encoded in the DNA strands (or in other not-yet-identified forms)? If the answer to this is yes, then one could in principle make a self-reproducing cell from non-living matter. In fact, man could in principle duplicate one of the existing life forms. Probably no scientist today can yet tell whether the answer is affirmative or not. Second is the factor of practicality. Even if it is possible to decipher the entire structure of a cell, it would probably be too complex to reproduce. A typical situation may be found in the following observation.
| The gene can . . . be synthesized, or created, directly, since the
nucleotide
sequence of the gene can be deduced from the amino acid sequence of its protein product. This procedure has worked well for small proteins like the growth regulatory hormone somatostatin which have relatively short stretches of DNA coding. But somatostatin is a tiny protein, only 14 amino acids long. With three nucleotides coding for each amino acid, scientists had to synthesize a DNA chain 42 nucleotides long to produce the complete hormone. For larger proteins, the gene-synthesis approach rapidly becomes highly impractical.15 |
Therefore it seems most likely that new life forms will be developed from existing forms rather than by direct production from non-living materials.
To press the inquiry one step further, might it be possible to change one life form to another one by genetic engineering for example, could one "kind" of life be transmuted into another by genetic engineering a rabbit into a dog (or whatever else might offend one's theological sensibilities)? To do so would of course require exact description of the cellular information of each kind a mind-boggling tast, it would seem. This, too, seems highly unlikely.
But all of this speculation is beside the point in a profound way: it
is one thing to duplicate an already existing structure with intelligent
direction; it is another thing entirely to produce such a structure without
the use of intelligent activity. And this is just the issue of creation
versus evolution. To make a digital computer after someone else has already
done so is not nearly as impressive as doing so for the first time. So
with life. Where did the original precise arrangement of life structures
come from? Secularists say it came from chance mechanisms plus some eternal
laws (most of which are still undiscovered). Christians say it came from
the mind of God.
Limits of Knowledge and the Impact on Secular Thought
Both Hoyle and Wald acknowledge the extreme improbability that the observed world could happen by chance, but end up postulating unknown laws or mechanisms to accomplish this impossible feat. One might be tempted to end all further dialogue and say, "What's the use?" since any formulation of a logical argument will be acknowledged and then promptly ignored. However, examples can be given to show that careful argument is not a waste of time, since there will be some who observe observe the facts of life and (like C. S. Lewis) are intellectually honest and sensitive enough to see the necessity of our conclusion. Concerning his own conversion, Lewis wrote:
| The Prodigal Son at least walked home on his own feet. But who can
duly adore
that Love which will open the high gates to a prodigal who is brought in kicking, struggling, resentful, and darting his eyes in every direction for a chance to escape?16 |
It is for such people that our effort proves worthwhile.
There is a strange element in all of this. To a person who has been taught that science is strictly logical, deductive and rational, it may seem odd that scientists such as we have quoted could formulate the dilemmas so precisely yet fail to take the obvious next step -- to acknowledge (or at least concede the possibility) that God is behind it all. However, this strange behavior is in fact consistent with the present state of science, which is far removed from the naive Sherlock Holmes and Tom Swift days.
Before World War I it was believed by many that scientific inquiry and the deductive process could ultimately solve any mystery and explain any apparent inconsistency. This belief is no longer held by scientists. The twentieth century rational sciences have been dealt mortal blows as they struggled to conquer the worlds of mathematics and science. These wounds take the form of barriers to knowledge that cannot be penetrated, now or ever. The barriers consist of laws or theorems, the truth of which cannot be doubted, which prevent a scientist from gaining a complete understanding of the object of his inquiry. Some examples of these laws follow.
The Heisenberg Uncertainty Principle is a law which limits the physicist's ability to probe the structure at the subatomic level and below. Basically, this principle says that one cannot look at something subatomic without destroying its structure, so that what is observed is not the same as what was there before the observation. Because of this, research at such levels consists of indirect and inferential observations. This is why such research seems to involve blowing things apart as expressed in the apt term, "atom smasher." What would you think of a great architect who set out to study the Taj Mahal by blasting it to pieces? At the least, many details are lost in the process.
The Goedel Incompleteness Theorem is to logic and mathematics what the Heisenberg Uncertainty Principle is to physics, but because the subject is logic the very basis for rational discussion the impact may be even greater. The Goedel Incompleteness Theorem states that it is impossible to build an axiomatic system (such as logic, geometry, rules of mathematics) such that all true theorems about the system are provable within the system (i.e., the system is complete) and at the same time the system can be shown to contain no self-contradictions (i.e., the system is consistent). Expressed in colloquial terms, the Goedel Theorem says this: You have a choice either (1) you can answer the questions you want answered at the risk of being self- contradictory, or (2) you can be free of contradiction and be unable to answer all the questions you want answered. You cannot be both consistent and complete. Or, to put it yet another way, you cannot be totally logical. Some of the truths that you hold will not be deductive; you must go out of your system to prove them.
How does this affect the evangelical Christian in his or her attempt to reach a modern scientist? Profoundly. Scientists have come to expect inconsistency in their lives. In fact, in modern science it is a mark of sophistication to realize that such things are inevitable. Perhaps this explains in part the "philosophical poverty of our times" that Wald noted in the quotation above. In the quest for knowledge (completeness), many scientists are willing to give up consistency; in fact, they get as comfortable and familiar with inconsistency as with an old pair of slippers. From this vantage point they look on a Christian apologist with bemusement, attributing to him a lack of sophistica- tion that indicates his naivete. This is a curious turn of events. It used to be that Christians were accused of being irrational; now they are accused of being rational!
An excellent current expression (perhaps hyper-expression) of the modern scientific view is found in Hofstadter's book mentioned earlier. Here the author carries to its logical limit the philosophical state of life under uncertainty and incompleteness, so that the absurd becomes normal and inconsistency a way of life. Woven though the book is a thick strand of Eastern mysticism, characterized by the nonsense sayings known as Zen koans. Nonetheless, in explaining "the way it really is," Hofstadter provides some amazing insights.
It is this admission of incompleteness that makes it easy for Hoyle, Wald and others to invoke "unknown natural laws" without seeming embarrasment.
One final limit to knowledge which may be relevant to the question of unlocking life processes concerns the problem of code-breaking. First, it is possible to code information in such a way that the result will appear to be indistinguishable from random noise. A channel may contain information in a sequence of apparently random and meaningless symbols, and not be decipherable no matter how smart the decoder may be. Second, and even more discouraging, it is possible for the exact coding method to be revealed and still the code cannot be broken. These facts, made public in the past twenty years, form the basis for so-called "open" codes, in which both the coding algorithm and the coded message are openly available for scrutiny, yet the codes are unbreakable unless one possesses the exact key (which may be only a few words in length). The U.S. Bureau of Standards has recently published a Data Encryption Standard which incorporates these findings and may ultimately remove the need for more than minimal security measures to protect encoded confidential information.17
It is interesting to note that in addition to containing the recognized
and decoded Genetic Key sequences in genes, the DNA molecules also contain
long stretches of "nonsense syllables" which have no known meaning. Suppose
that these stretches contain encoded genetic information for some of the
processes that go on in addition to protein formation. These results in
coding theory described above indicate that it is entirely possible that
the information may be encoded in such a way that scientists will never
be able to break the code. The point is that God can, if he desires, place
all of the genetic life information before the very eyes of scientists,
without the slightest risk of revealing the secret that unlocks the process.
What this means with regard to the DNA molecule is this: even if
it truly contains all genetic information coded within it, and even
if scientists are able to reconstruct its exact form, and even if
scientists were to learn all the laws of nature that are used to encode
the DNA molecule, it may still be totally impossible to create new life
forms beyond the species and variations which already exist, or even to
read all the genetic information of the DNA molecule.
Summary
The genetic research of the past few decades has done little to erode the Christian view of God as Creator and life forms as the highest evidence of his creative handiwork. The evidence favors the view that elementary life processes involve an overwhelming amount of primary information, far more than can reasonably attributed to random chance. The only way around this conclusion is to accept as an article of faith the existence of unknown natural laws of sufficient power to account for this information, e.g., to account for the original formation of the gene coding sequences. In the absence of such faith, there is insufficient time (by anyone's reckoning) and insufficient matter in the entire visible universe to produce life as we know it.
As complex as is the known process of forming genetic molecules and
proteins, there are still considerable gaps of understanding, and the identity
of the medium containing much of the apparent information in the cell (such
as that controlling transport mechanisms) is unknown. Because of the size
and complexity of the known information channels (DNA, etc.), it
seems highly unlikely that mankind will be able to synthesize life from
nonliving material, even if all of the necessary information is in principle
available in the molecular structure of existing life forms.
References
1 (page 3). George Wald, "The Origin of Life," Scientific American (Aug 1954), reprinted in The Chemical Basis of Life (San Francisco: W.H. Freeman, 1973), pp 9-17.
2 (page 7). Impacts of Applied Genetics: Micro-Organisms, Plants and Animals, Office of Technology Assessment Report to the Congress of the United States (Washington, DC: Government Printing Office, 1981), esp. chapter 2; see also Maya Pines, Inside the Cell (Washington, DC: Government Printing Office, 1979).
3 (pp 8-9). Source: Office of Technology Assessment.
4 (p 9). Pines, Inside the Cell, p 29.
5 (p 10). Impacts of Applied Genetics, p 38.
6 (p 10). Fred Hoyle, Ten Faces of the Universe (San Francisco: Freeman, 1977); quoted selections are from pp 158, 79, and 163, respectively.
7 (p 14). Wald, "Origin of Life," p 14.
8 (p 16). Douglas R. Hofstadter, Goedel, Escher, Bach: An Eternal Golden Braid (New York: Basic Books, 1979), pp 504ff.
9 (p 17). Ibid., p 162.
10 (p 18). James M. Orten and Otto W. Neuhaus, Human Biochemistry 9th ed. (St. Louis: C.V. Mosby, 1975), fig 3-17, p 63.
11 (p 18). Hofstadter, Goedel, Escher, Bach, p 528.
12 (p 19). Pines, Inside the Cell, p 75.
13 (p 20). Impacts of Applied Genetics, pp 39-41.
14 (p 21). Ibid., pp 61ff.
15 (p 21). Ibid., p 41.
16 (p 22). C. S. Lewis, Surprised by Joy (New York: Harcourt, Brace and World, 1955), p 229.
17 (p 24). Data Encryption Standard, FIPS Publication 46, U.S. Dept. of Commerce, National Bureau of Standards, 1977.